Paper: DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Authors: Tianhao Qi, Shancheng Fang, Yanze Wu, Hongtao Xie, Jiawei Liu, Lang Chen, Qian He, Yongdong Zhang
Code & Dataset: GitHub
研究背景
- 基于扩散模型的文本-图像生成模型(T2I)的发展,一些工作尝试引入参考图像作为生成模型的状态,风格图像就是其中一种
- 利用T2I的已有工作
- 基于本文转换的方法,将风格图像编码为文本嵌入空间的编码,这种图像到文本的模态转换容易导致信息的丢失
- 针对风格微调参数的方法容易导致过拟合,且在现实生产中不具有实用性
- 通过图像编码器提取风格图像特征
- T2IAdapter-Style 和 IP-Adapter 使用 Transformer 作为图像编码器,以 CLIP 图像嵌入作为输入,并通过 U-Net 交叉注意层利用提取的图像特征
- BLIP-Diffusion 通过 Q-Former 将图像嵌入转化为文本嵌入空间,作为扩散模型文本编码器的输入
研究方法
Querying Transformer(Q-Former)
- 由 Image Transformer 和 Text Transformer 组成,共享 Self-Attention 层参数
- Image Transformer 提取与本文内容最相近的视觉特征
- 输入:图像特征和可学习 Queries
- 由于共享 Self-Attention 层参数,Queries 可同时与图像特征和文本特征进行交互
- Text Transformer 作为输入文本的编码器和解码器
提取风格特征和内容特征
解耦风格特征与内容特征提取
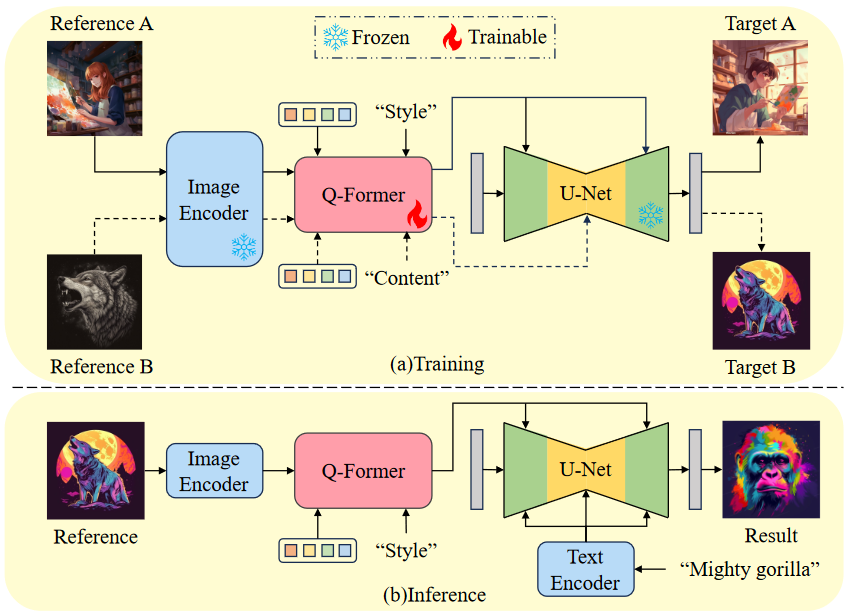
- STRE(Style Representation Extraction)
- 使用风格相同的图像作为扩散模型的风格图像和输出目标
- CLIP 提取的风格图像特征作为Q-Former输入的图像特征,文本“Style”提取特征作为Q-Former的文本特征,内部做交叉注意力,输出与文本相关的图像特征作为风格特征
- SERE(Content Representation Extraction)
- 使用主体相同但风格不同的图像作为扩散模型的风格图像和输出目标
- CLIP 提取的风格图像特征作为Q-Former输入的图像特征,文本“Content”提取特征作为Q-Former的文本特征,内部做交叉注意力,输出与文本相关的图像特征作为内容特征
Disentangled Conditioning Mechanism(DCM)分离条件机制
在使用Diffusion模型去噪的过程中,提取的风格特征和语义特征将作为交叉注意力层的状态输入,从而引导模型更有效地分离风格特征和语义特征
模型使用Stable Diffusion v1.5作为文本-图像生成模型,将16个交叉注意力层编号为0-15,其中,4-8层为Coarse层,其余为Fine层
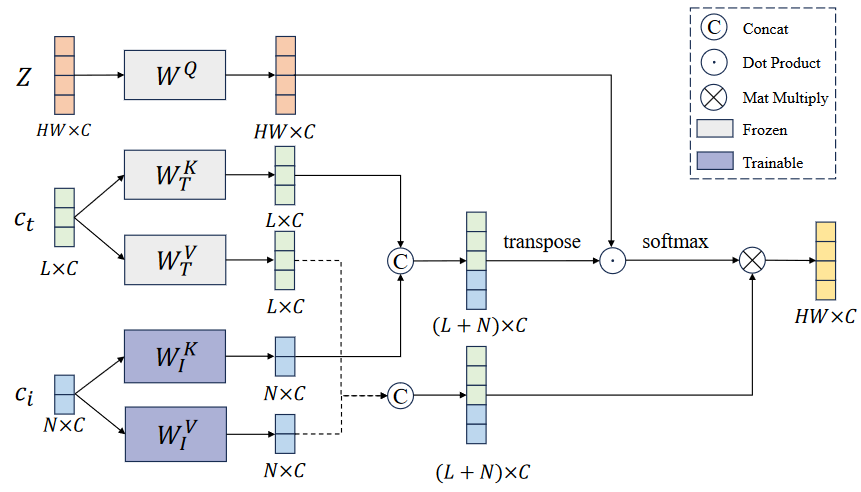
- 输入
- 风格信息将作为高分辨率Fine层的状态输入,使得提取的风格特征更注重笔画、纹理和颜色等细节信息
- 语义信息将作为低分辨率Coarse层的状态输入
- 网络结构 Text-image Crossattention Layer
- 1)计算图像特征
的Key和Value - 2)固定参数计算文本特征
的Key和Value - 3)计算Query
- 4)分别拼接图像和文本的Key以及图像和文本的Value
- 5)计算交叉注意力
- 1)计算图像特征
构建成对数据
准备主体词列表和风格词列表,组合得到相同主体或相同风格的提示词对,利用Text-to-images模型生成图像
- 构建文本提示词
- 1)主体词:人物、动物、物体和场景四种类别,12000
- 2)风格词:艺术风格、艺术家风格、笔触等,650
- 3)1个主体词对应约14个风格词构成提示词组合,160000
- Midjourney生成图像 1个提示词生成4张分辨率为
的图像,上采样到 后,构建文本-图像对,1060000 - 成对图像选择
- 1)风格特征学习:随机选择相同提示词生成的图像构成图像对
- 2)内容特征学习:随机选择主体词相同但风格不同的提示词对应的图像对