Paper: Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
Authors: Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue, Yangyu Tao, Jianchen Zhu, Kai Liu, Sihuan Lin, Yifu Sun, Yun Li, Dongdong Wang, Mingtao Chen, Zhichao Hu, Xiao Xiao, Yan Chen, Yuhong Liu, Wei Liu, Di Wang, Yong Yang, Jie Jiang, Qinglin Lu
Code & Pretrained Model: GitHub
背景
- 现有一些基于 Diffusion 的文生图模型,如 DALL-E、SD 和 Pixart 缺乏对中文提示词的理解,而 AltDiffusion、PAI-Diffusion 和 Taiyi 这一类具有中文理解能力的模型则仍有进步空间
基于 DiT 的模块改进
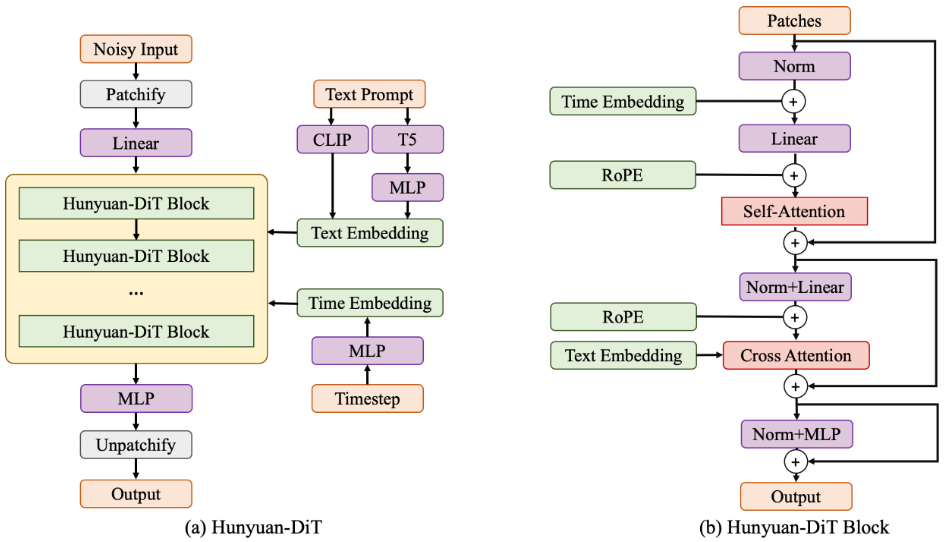
图像编码器
使用预训练 VAE 提取图像编码用于学习数据分布,SDXL 中的 VAE 相比于 SD1.5 中的 VAE 有较大的提升
文本编码器
使用预训练中英双语 CLIP 模型以及多语种 T5 模型提取文本编码
混元 DiT
- 按照
的大小分块 - 为了提升模型在细粒度文本条件表现,在特征提取模块使用交叉注意力层融合文本特征
- Transformer 块包含编码块和解码块,块中包含了自注意力-交叉注意力-FFN
- 在解码块增加了与编码块之间的跳层链接
- 训练时使用 v-prediction 的方式具有更好的表现
v-predition 相关资料 在使用 v-prediction 方法时,模型不直接预测噪声 ε,而是预测了一个加权后的量 v,这个量结合了噪声 ε 和原始数据 x 的信息,能在采样步骤较少的情况下提供有效的信号来指导采样过程
位置编码和多分辨率图像生成

- 使用二维 RoPE 对绝对位置和相对位置进行编码
- 为了实现多分辨率图像生成,尝试了两种类型的编码
- Extended Positional Encoding,随着宽高的不同,编码结果也会有巨大的差异
- Centralized Interpolative Positional
Encoding,定义边界
为编码结果变化的范围,且以图像中心为编码 0 点
提升训练稳定性
- 使用 QK-Norm,在计算 Q、K 和 V 之前增加归一化层
- 在跳层模块后增加归一化层,从而避免梯度爆炸
- 使用 FP32 进行训练避免溢出