Img-Diff
Paper: Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Authors: Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, Ying Shen
Code & Dataset: GitHub
Application: 提出的组件和端到端构建工作流程在 Data-Juicer 中作为数据处理算子和可配置文件来实现
专业名词
- Multimodal Large Language Models (MLLMs)
- Visual Question Answering (VQA)
- Image Difference Captioning (IDC) 专注于图像之间的细微差别而不仅仅是物体描述
背景
提升多模态大语言模型的表现通常有两种路径,一种是提升模型架构,另一种则是提升数据质量
多数多模态大语言模型进行两阶段训练,第一阶段训练实现图像-文字数据对的模态对齐,第二阶段则注重通过 Instruction Tuning 数据集微调提升模型的问答能力
通过提升图像-文字数据对的数量可以提升模型的语义对齐能力,但有可能影响模型的问答能力,因此更多工作集中于研究 Instruction Tuning 数据集的增强
提出方法与 InstructPix2Pix 类似,采用 Prompt-toPrompt 技术以及生成模型 Stable-Diffusion-XL 来生成相似图像对,在生成阶段结合了多个筛选阶段来确保数据质量,强调模型关注特定区域而不是整个图像的差异
数据合成方法
利用对比学习的原理来生成 MLLM 图像-文本数据。该方法侧重于替换图像对中的对象,引导 MLLM 识别特定区域的相似性和差异
- Step1. 创建相似图像并形成图像对,这些图像对之间的唯一区别是图中的对象
- Step2. 提出差异区域生成器(Difference Area Generator),提取包含图像对之间的对象差异的边界框
- Step3. 提出差异描述生成器,通过 MLLM 为具有对象差异的区域生成描述性文本,并创建问答对,例如“该区域中哪些对象发生了变化?”
过程中应用的大模型
Vicuna-1.5-13B 魔塔
由 LMSYS 研发的,基于 Llama 2 微调的 Transformer 架构自回归语言模型
Stable-Diffusion-XL Hugging Face
由文字生成图像的潜在空间扩散模型:1)UNet 的大小是原来的 3 倍,引入文本编码器编码器(OpenCLIP ViT bigG/14)与原始文本编码器相结合;2)引入大小和裁剪条件,以防止训练数据被丢弃,并更好地控制生成的图像应如何裁剪;3)引入两阶段模型过程,基础模型(也可以作为独立模型运行)生成图像作为优化模型的输入,该模型添加了额外的高质量细节
CLIP Github
CLIP (Contrastive Language-Image Pre-Training) ,一个在图像-文字数据对上预训练的模型,可以通过给定图片判断最相关的文字片段
FastSAM Github
SAM 作者提出的具有更快推理速度的分割模型
BLIP
BLIP(Bootstrapping Language-Image Pre-training),一个统一视觉语言理解与生成的预训练模型,可以通过图像生成图像标注
LLaVA-NEXT Github
多模态大模型
全流程梳理

模块一:创建相似数据对
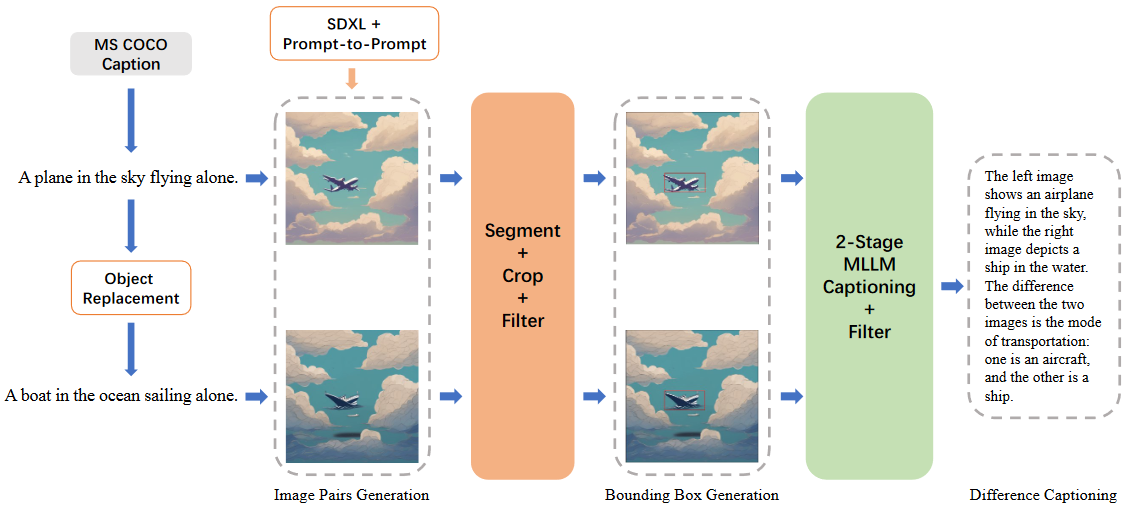
- 从 MS COCO 获取 118K 图像描述
- 使用 Vicuna-1.5-13B 替换图像描述中的对象
- 输入 Prompt:“这里有一个句子:‘INPUT’。请仅将这句话中的一个宾语替换为另一个宾语。”
- INPUT 为原始描述,LLM 生成替换后的描
- 使用生成的描述文本对,利用图像生成模型 Stable-Diffusion-XL 和图像编辑技术 Prompt-to-Prompt 生成仅替换少量对象的图像对
模块二:差异区域生成器(Difference Area Generator)
该模型用于识别图像对之间对象差异的位置 由于预训练的目标检测模型有检测类别的限制,所以生成器基于分割方法和图像相似度比较识别差异位置,如下图所示
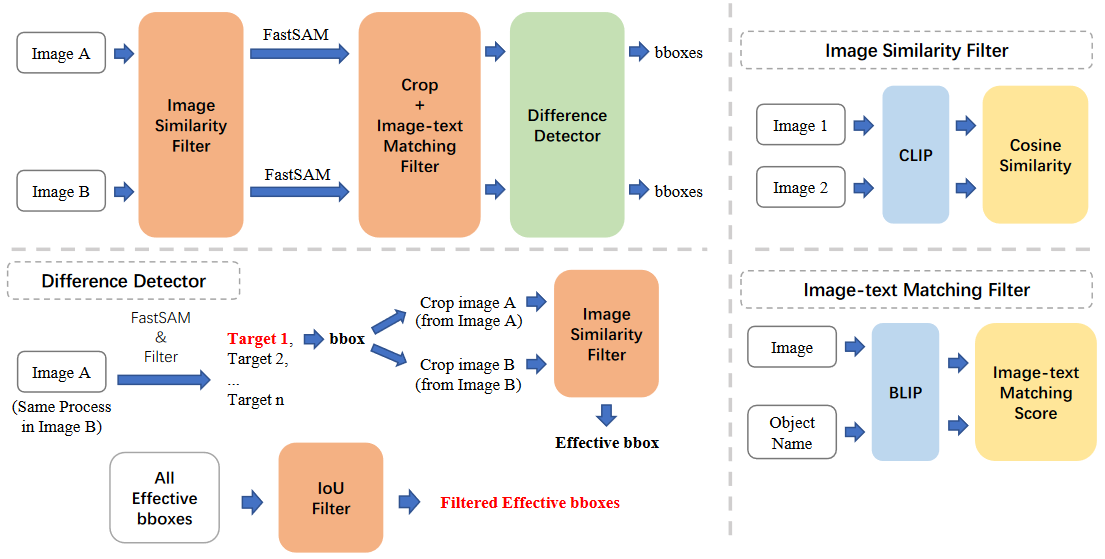
- 通过 Image Similarity Filter 获得相似度高但不完全相同的图像对
- 使用 FastSAM 分割每张图像
- 根据分割获得的边界框信息裁剪图像,并使用 Image-text Matching Filter 判断裁剪后的子图像是否存在有效对象
- 使用 Difference Detector 来确定图像对的边界框区域之间是否确实存在差异,并进行 IoU 过滤以去除重叠的边界框,最终获得有效的边界框信息
Filter1:Image Similarity Filter
根据图像相似度过滤图像对
计算流程
- 该模块首先使用 CLIP 提取图像特征,然后计算特征间的余弦相似度
- 若余弦相似度在预设阈值内,则图像对将被视为有效
应用阶段
- 在使用 FastSAM 进行分割之前,使用该模块来确保图像对高度相似但不完全相同
- 在 Difference Detector 阶段,根据边界框信息裁剪子图像后,使用该模块过滤子图像对并仅保留不同的子图像对
Filter2:Image-text Matching Filter
确定图像是否包含有效对象(即已替换或正在替换的对象)
计算流程
- 该模块首先使用 BLIP 提取图像特征,然后将其与对象名称的文本特征进行比较
- 当图文匹配分数落在预设阈值内时,则认为图像包含有效对象
应用阶段
- 根据分割信息进行子图像裁剪后,使用该模块来确定子图像是否包含有效对象并获得相应的有效边界框
Filter3:Difference Detector
确定图像对的边界框区域之间是否存在差异
计算流程
- 根据边界框从图像 A 和 B 中裁剪两个子图像
- 通过 Image Similarity Filter 过滤子图像对,仅当差异足够显著时才认为边界框有效
- 处理完所有边界框后,使用 IoU 方法过滤重叠的边界框,仅保留差异程度较高的边界框,最终输出所有有效边界框
模块三:差异描述生成器(Difference Captions Generator)
获得有效的边界框区域后,使用 Difference Captions Generator 生成有关这些区域内容的差异描述 图像对可能包含多个差异,而单个描述无法完全捕获所有差异,因此每个描述仅关注一个图像对中的一个边界框
该模块分为两个阶段,如下图所示
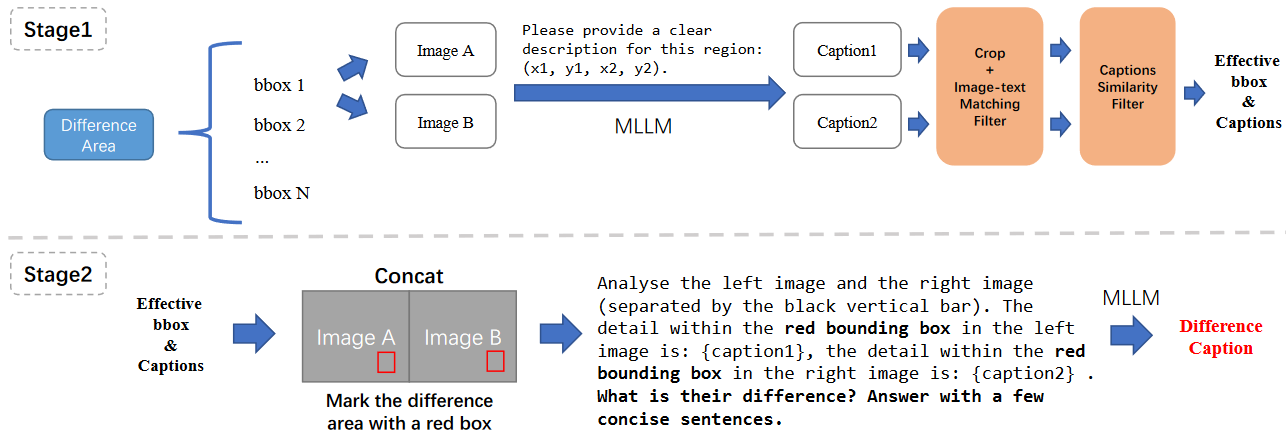
- 第一阶段,模型为边界框区域生成内容描述,然后使用 Image-text Matching Filter 和 Captions Similarity Filter 筛选带内容描述的边界框
- 第二阶段,模型使用内容描述和用红框标注的图像生成差异描述
阶段一:对象标注和筛选
- 对于每个图像对,首先选择图像之间相似度最低的 N 个边界框区域(本项目中 N 设置为 5)作为候选区域
- 对于每个边界框,我们使用 MLLM LLaVA-NEXT 来描述其相应的区域
- 第一个筛选过程,通过 Image-text Matching Filter 检查区域与描述是否对应
- 第二个筛选过程,通过 Captions Similarity Filter 评估描述之间是否存在差异,使用 CLIP 来获取文本特征并计算它们之间的余弦相似度,当分数足够低时,可认为两个标题不同
- 筛选完成后,获得的有效的边界框和描述将用于后续的差异描述生成
阶段二:差异描述生成
对于每个图像对的各个有效边界框生成差异描述
- 根据边界框信息在图像中绘制两个红色框,突出显示差异以便于定位
- 为 MLLM LLaVA-NEXT 提供边界框区域的描述,并引导模型根据内容描述和红色框生成差异描述